MS COCO数据集的下载、介绍与使用(目标检测)(一) |
您所在的位置:网站首页 › coco mini › MS COCO数据集的下载、介绍与使用(目标检测)(一) |
MS COCO数据集的下载、介绍与使用(目标检测)(一)
|
MS COCO
下载数据集数据集介绍目标检测标注文件
COCOAPI的使用win下make命令的使用
继续配置COCO api模型微调特征提取采用预训练模型的结构训练特定的层,冻结其他层
References
博主最近一直都在潜心研究YOLOv5,先用的VOC数据集做了训练,发现性能还不错,现在打算利用MS COCO对于模型进行复现。 博主看的第一篇论文所用的数据集就是有20个类别的Pascal VOC数据集和80个物体类别的MS COCO,这些数据集在时间的推移下都变得越来越大(比如Pascal VOC 从2007的400M到后来的VOC2012快2个G) 今天,我们就来学一学MS COCO数据集的使用方法。 下载数据集微软发布的 COCO 数据库是一个大型图像数据集, 专为目标检测、分割、人体关键点检测、语义分割和字幕生成而设计,用于Object Detection + Segmentation + Localization + Captioning。 下载链接如下,数据包括了物体检测和keypoints身体关键点的检测: train数据 http://images.cocodataset.org/zips/train2017.zip http://images.cocodataset.org/annotations/annotations_trainval2017.zipval验证数据集 http://images.cocodataset.org/zips/val2017.zip http://images.cocodataset.org/annotations/stuff_annotations_trainval2017.ziptest验证数据集 http://images.cocodataset.org/zips/test2017.zip http://images.cocodataset.org/annotations/image_info_test2017.zip直接用迅雷下载的,感觉速度还行。 下载并解压之后发现annotation全部都合并了,然后还有test2017、train2017、val2017分别对应测试集、训练集和验证集。 在annotation中,有很多分类的json格式文件,其中文件对应的任务如下: instances:目标检测captions:字幕生成,图片描述person_keypoints:关键点检测stuff_train/val:素材分割(Stuff Segmentation)在官网给出的五大任务中,还有一个任务叫做panoptic segmentation全景分割,是和图像分割有关的。官网的data format介绍 deprecated-challenge2017文件夹下的数据没有annotations,简单的对数据集进行训练集和验证集的划分。 image_info:图片信息,应该是比赛中用到的吧 这里只详细介绍目标检测任务的json文件。 打开json文件已经把我的眼睛看花了,还是看一下官网介绍 annotation{ "id": int, "image_id": int, "category_id": int, "segmentation": RLE or [polygon], "area": float, "bbox": [x,y,width,height], "iscrowd": 0 or 1, } categories[{ "id": int, "name": str, "supercategory": str, }]以下是我从instances_val2017.json中随便抽取的一些内容: "annotations": [{ "segmentation": [[252.05,222.25,243.14,209.82,248.06,204.43,254.63,209.59,254.16,205.84,252.52,202.79,256.5,199.04,264.71,196.46,264.94,201.38,260.49,203.49,260.96,205.13,266.35,202.79,271.51,200.91,275.97,203.73,277.61,225.77,273.62,228.35,270.57,230.69,263.3,229.05,259.55,224.59,255.1,221.78]], "area": 716.9797500000005, "iscrowd": 0, "image_id": 50145, "bbox": [243.14,196.46,34.47,34.23], "category_id": 2, "id": 1335206 }] //存放各类别与supercategory之间的映射 "categories": [{ "supercategory": "person", "id": 1, "name": "person"}]每个对象实例的标注都包含一系列字段,包括对象的类别ID(category_id) 与分段掩码(segmentation) segmentation的编码格式取决于实例是表示单个对象(iscrowd = 0,在这种情况下使用polygen)还是对象集合(iscrowd = 1,在这种情况下使用RLE) 为每个对象提供一个封闭的边界框(框坐标是从左上角的图像角测量的,并且是0索引的)。 其中“bbox”属性为实例的边界框(bounding box)。这四个数字的含义为左上角横坐标、左上角纵坐标、宽度、高度,这个框为大致画出。 标注结构的 categories 字段存储各个category(id,name) 和 supercategory 名称(supercategory)的映射。 如类别bird、dog、sheep、elephant、zebra的super category为animal。 readme文件如下 COCO API - http://cocodataset.org/ COCO is a large image dataset designed for object detection, segmentation, person keypoints detection, stuff segmentation, and caption generation. This package provides Matlab, Python, and Lua APIs that assists in loading, parsing, and visualizing the annotations in COCO. Please visit http://cocodataset.org/ for more information on COCO, including for the data, paper, and tutorials. The exact format of the annotations is also described on the COCO website. The Matlab and Python APIs are complete, the Lua API provides only basic functionality. In addition to this API, please download both the COCO images and annotations in order to run the demos and use the API. Both are available on the project website. -Please download, unzip, and place the images in: coco/images/ -Please download and place the annotations in: coco/annotations/ For substantially more details on the API please see http://cocodataset.org/#download. After downloading the images and annotations, run the Matlab, Python, or Lua demos for example usage. To install: -For Matlab, add coco/MatlabApi to the Matlab path (OSX/Linux binaries provided) -For Python, run "make" under coco/PythonAPI -For Lua, run “luarocks make LuaAPI/rocks/coco-scm-1.rockspec” under coco/首先介绍了一下COCO数据集的五个常用任务目标检测、图像分割、人体姿态检测、素材分割、图片描述 然后提供了Matlab\Python\Lua三个版本的API用于json版本annotations的加载、解析、可视化 首先先把图把图片和所需的标注放在coco/images、coco/annotations目录下(自行创建) 由于不知道image_info_test是做什么的就都保留了,没删掉,可能也没啥用。 由于不知道image_info_test是做什么的就都保留了,没删掉,可能也没啥用。  安装一下API
For Python, run "make" under coco/PythonAPI 安装一下API
For Python, run "make" under coco/PythonAPI
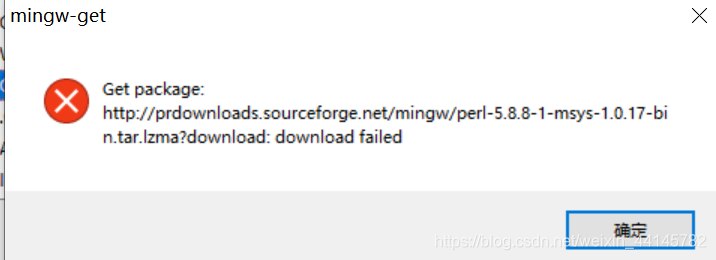
博主这里利用的是PythonAPI 跟着这篇简书文章安装即可https://www.jianshu.com/p/6eab5567415d win10系统装的时候说有两个包没找到,先忽略掉。(貌似我装过了?)  右击->属性->高级系统设置 右击->属性->高级系统设置
然后就能够使用make命令了,报了和原题主一样的错误。  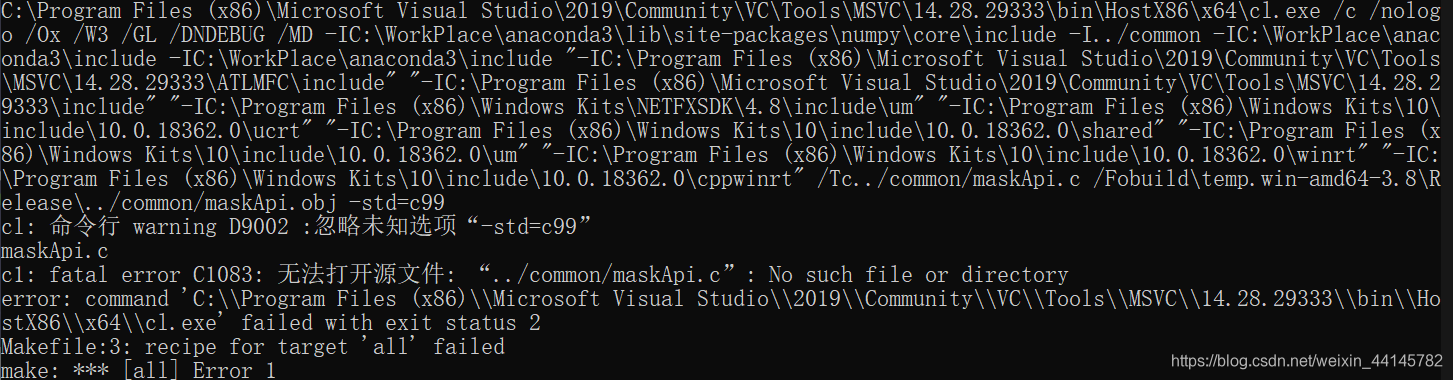 模型微调
模型微调
一些训练可以用的技巧,mark一下 特征提取 将预训练模型当做特征提取器来使用去掉输出层,将剩下的整个网络当作一个特征提取器,从而应用到新的数据集中 采用预训练模型的结构 预训练模型的模型结构保持不变将所有的权重重新随机初始化根据自己的数据集进行训练 训练特定的层,冻结其他层 对预训练模型进行部分的训练将模型起始的一些层的权重锁定,保持不变重新训练未锁定的层,得到新的权重 References COCO 数据集的使用 https://www.cnblogs.com/q735613050/p/8969452.htmlMS coco数据集下载 https://blog.csdn.net/daniaokuye/article/details/78699138数据集COCO在目标检测的介绍与使用 https://blog.csdn.net/winycg/article/details/100185794?ops_request_misc=&request_id=&biz_id=102&utm_term=mscoco数据集 目标检测的使用&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduweb~default-7-100185794.pc_search_result_before_js什么是预训练模型 https://blog.csdn.net/weixin_42631192/article/details/106585567win下之make命令的使用 https://www.jianshu.com/p/6eab5567415d |
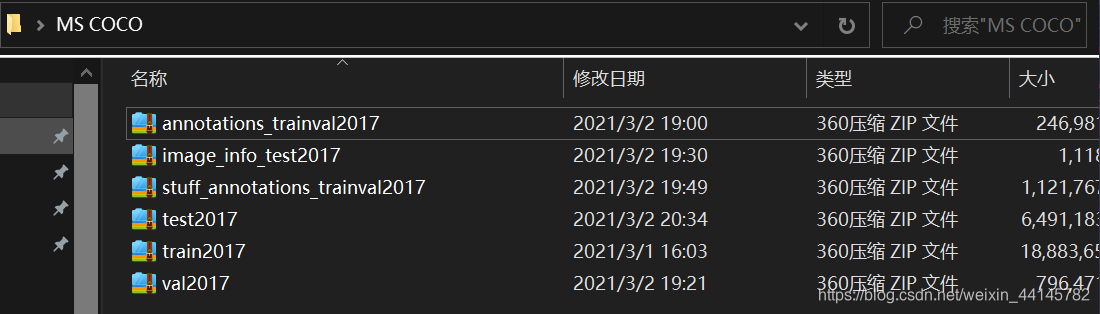

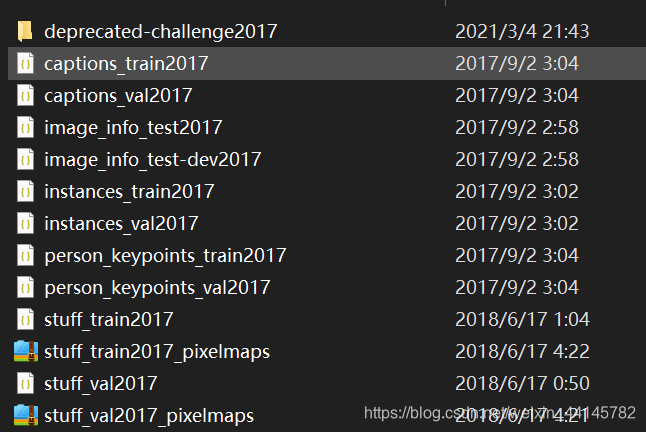
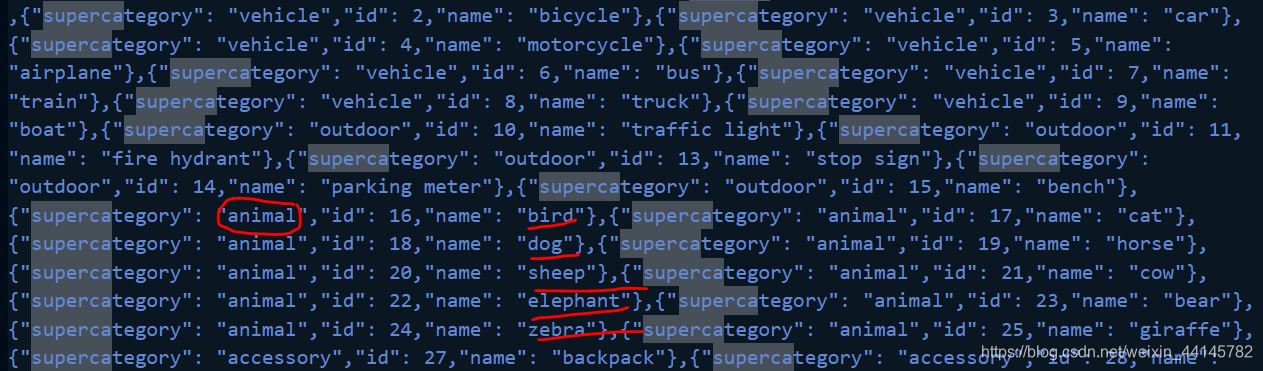 coco2017数据集共80小类,类别id号不连续,最大为90。
coco2017数据集共80小类,类别id号不连续,最大为90。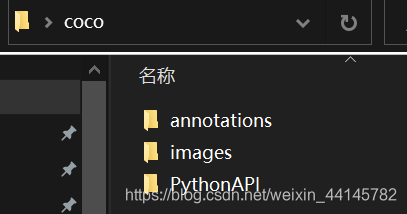 我的win10系统还没装make,一些按照linux下编写makefile可能会在Windows下出错,先安装一下make吧,安装过的自行跳过。
我的win10系统还没装make,一些按照linux下编写makefile可能会在Windows下出错,先安装一下make吧,安装过的自行跳过。 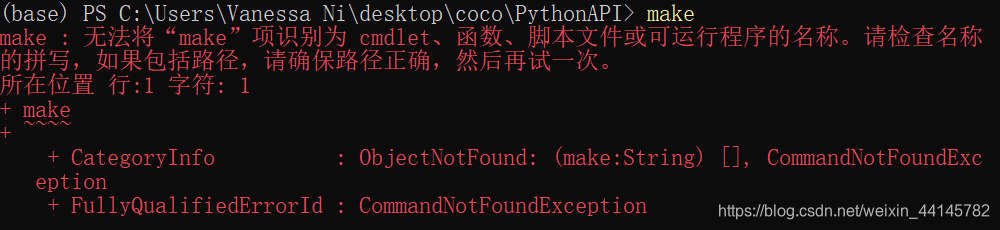

【本文地址】
今日新闻 |
推荐新闻 |